Indoor Location & Navigation コンペ振り返り
Indoor Location & Navigation というコンペで9位入賞。目標だった Kaggle Master になったので振り返り。これはチームメイトである @KaggleSaito さんとの成果である。
どういうコンペか?
与えられたスマホセンサーデータ(Wifiなど)からショッピングモールでのフロアと位置を推定する。これがうまくいけば、例えばイオンモールの無印の近くにいるときに適切なクーポンをユーザーに届けられるかもしれない。
評価指標
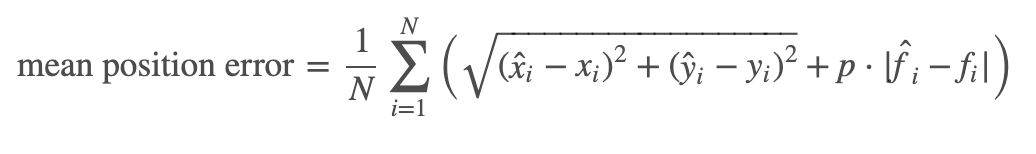 大まかに言うと真の (x, y) との距離が小さければよい。何階か?を外すと大きなペナルティ。
大まかに言うと真の (x, y) との距離が小さければよい。何階か?を外すと大きなペナルティ。
自分のモデル
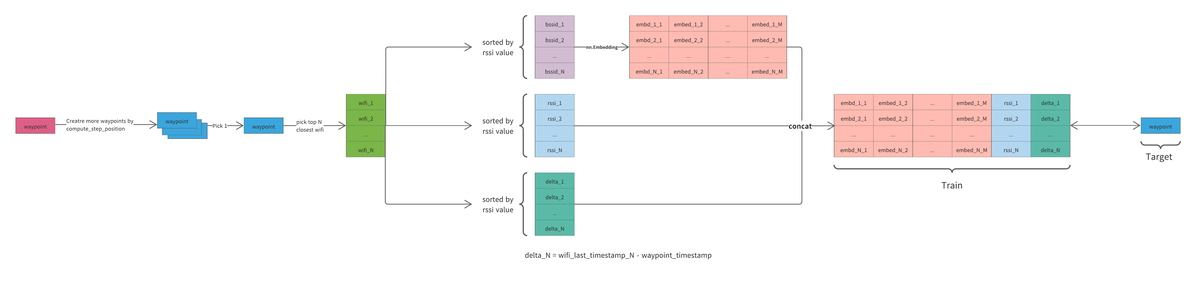 他のチーム同様 Wifi データをメインに LSTM/GRU のモデルで位置を推定し、post processing で精度を高めた(大きな画像へのリンク)
他のチーム同様 Wifi データをメインに LSTM/GRU のモデルで位置を推定し、post processing で精度を高めた(大きな画像へのリンク)
{kind=link}
他のチームとの差別化要因は
- Training Data を水増しできたこと。コンペの host が提供する utility 関数に ``compute_step_postion``` という関数がありセンサーデータを人間の歩み(step) に変換できる。これを以下で述べるアプローチと組み合わせると精度が上がった。
- Kouki さんが Shareししてくれた Wifi データを LSTMにに入力する方法の視点を変えて、より自然な waypoint ベースの training set を生成した。
- Saito さんの提案ではじめた Pseudo Labeling がよく効いた。
- LSTM/GRU の Stacking。
- Saitoさん主導の Post Processing。
- floor image を利用しての hallway map を作成。
- hand labeling ではない waypoint の生成
試したがうまく行かなかったもの
- Transformer
- hallwayからハズレた場合に大きなペネルティを与える custom loss(実装大変だった)
作業環境・実験管理
- Colab Pro のハイメモリをメインで使った。データのサイズが大きくメモリに載せるのが大変だった。ML力よりもエンジニアリング力がある自分としてはとても有利だったと思う。
- Colab Pro は notebook 機能はほぼ使わず。安価に GPU が使える実行環境として利用した。
- 実行環境の入出力(データセット)は API を利用して Kaggle Datasetを使う
- 以前は Google Drive だったが圧倒的に Kaggle datasetののほうが良かった。
- 実行ボタンを押すと、Kaggle dataset からデータダウンロード、実行 scriptを git からチェックアウト。学習が終わったら結果を Kaggle dataset にアップロード。
- 各実験ごとに番号を振り、その notebookで実行ボタンを押せばすべてが再現するようにした。
- コーディングは Localの Visual Studio Code on Macで。
- Docker は非力なローカルマシンでは足枷にしかならなかったので今回はやめた。
- 実行環境の入出力(データセット)は API を利用して Kaggle Datasetを使う
自分が伸び悩んでいたところがわかった
自分は長らく金メダルが取れずに伸び悩んでいたのだが。どうすればよかったのかがようやく分かった。
データをよく見ること
EDA しよう。データを良く見ようとはよく言われることだ。本にも書いてある。分からないなりに EDA notebook を作り visualize したことは何度でもあるか正直ピンときてなかった。今回うまく行った方法は、他人が書いたデータプロセスコードを行レベルで完全に理解し数倍に高速化すること。その過程で「分かった」と思っていたが全然肌感覚で理解していなかったデータの関係が見えてきた。そして高速化・自分のコードに書き直したことでその先のステップに進みやすかった。
ツールや API への習熟
これも当たり前すぎるかもしれない。有名な Grand Master Abhishekさん のYouTube 動画を見たときに衝撃を受けたのを覚えている。pandas の各種機能 keyward 引数など調べずにスラスラ書いていた。一方自分はすべて検索しながらコピペしながらである。
このコンペでは上記の高速化があったので、たくさんコードを書いた。今なら何も見ずに pandas の groupby や LSTM モデル・データセットのコードを書く自信がある。