Machine Learning Design Patterns
Scaling
- Min-max & clipping は一様分布に良い
- Z-score は正規分布に良い。
- input data によっては non-linear な変換の方が適切。例えば Wikipedia page views。これは正直意識してなかった。
この視点で圧力コンペのデータでやってみた(02-01-scaling.ipynb)
Categorical
入力が array of categorical である場合は考えたこともなかった。dummy と one hot encoding の違いを理解した。
Design Pattern 1: Hashed Feature
Kaggle では経験のないパターン。新しい ID や cold start にも対応できるのが良い。学習データにはない空港が建設された場合どうするか。というのはわかりやすい例だった。感覚的には hash が衝突して全く関係のない入力同士が同じ bucket に入るとうれしくないような。categorical_column_with_hash_bucket の使用例がなかったので書いてみた。 (https://github.com/higepon/Machine-Learning-Design-Patterns/blob/main/pattern-1-hashed-feature.ipynb
Design Pattern 2: Embeddings
Embeddings は散々使い倒してきたので実装はしない。Embedding size の目安の指標は知らなかったのでメモ。Image の auto encoder による dimension reduction は使ったことないので今度やる。
one rule of thumb is to use the fourth root of the total number of unique categorical elements while another is that the embedding dimension should be approximately 1.6 times the square root of the number of unique elements in the category, and no less than 600
Design Pattern 3: Feature Cross
Kaggle で行われている feature engineering の中で最もシンプルなもの。モデルには見えないものを作って見せる。もしくはモデルには見えるかもしれないが学習に時間がかかるものを直接見せる意味合いがある。Crossed feature の見つけ方を書いてくれたらもっと良かった。
Design Pattern 4: Multimodal Input
種々の feature を concatenate して feed するやつ。きちんとした名前がついているのは知らなかった。Kaggle でも多用されてる。別種の embeddings を concatenate するとか。
Design Pattern 5: Reframing
Reframing とは Machine Learning Model の Output の種類を変えること。例)Regression が自然なのに Classification にする(またはその逆)。
- 例:降水量予測問題
- 問題
- Output は降水"量" なので実数を予測する regression タスクだろうか?
- 実際にやってみると同じ feature に対して降水量が 0.3 cm のときも 0.5 cm の時もある。
- 解法
- そもそも降水は確率的な振る舞いをするので 1 つの実数値を予測する Regression モデルは合っていないのかも。
- Classification model として Reframe する。
- なぜ良いか?
- bucketing により precision をある程度犠牲にしてしまうが離散化した classification の方が複雑な target を学習するのがうまいらしい。
- 赤ちゃんの体重の確率分布の話はとても面白かった。best root mean square error が stddev に一致するのも納得。
- 問題
- 逆の例:ユーザーの過去見た video id とその raring (1-5) を入力に次に見る video を1つ recommend する classification problem。
- Regression problem として video の user space での characteristics を output する
Design Pattern 6: Multilabel
- 画像の中にいる複数の動物名を特定する。文章からふさわしい複数の tag を生成する。
- 単純な classification なら softmax + argmax で選ぶ。dog, cat, rabbit から1つ選ぶなら [.89, .02, .09] で argmax。足すと1になることに注意。
- 解法
- sigmoid で [.92, .85, .11] のように各要素で 0-1 の確率を出す。
- 各種 classification まとめ
- binary classification
- softmax は冗長なので sigmoid + binary cross entropy loss。
- multilabel
- sigmoid + binary cross entropy loss。
- sigmoid 結果の parse 方法
- softmax + argmax のようには行かない。各クラス label を採用するか threshold が必要。
- binary classification
Design Pattern 7: Ensembles
- Model の Prediction に誤差がある。なぜか?
- (1) 減らせない誤差:dataset にある noise、問題の framing、よくない訓練データなどに由来する誤差。
- (2) bias=Underfit.
- (3) vairiance=overfit.
- Ensemble 手法
- Bagging: high variance を解決する。k個のモデルに対して k 個の subsample された学習データを用意。各モデルの出力を aggregate する(mean / majority vote)
- Boosting: Ensemble Model は各サブモデルよりも capacity を上げるので bias を減らす方向に動く。Gradient Boosting の boosting。
- Dropout は bagging の一種と考えることもできるというのは目から鱗だった。
Design Pattern 8: Cascade
- 問題
- usual(よく起きる)とunusual(滅多に起きない)の両方に対して値を予測したい。モデルは滅多に起きないことを無視する方向で学習してしまう。
- unusualの方をoverweightする方法もあるがusualの方が精度が落ちてしまう
- 直感的には以下のCascade Design Patternを思いつくだろう
- usualかunusualかを予測するモデルを作る
- usualケースを予測するモデルを作る
- unusualケースを予測するモデルを作る
- 本番時のpredictionでは1つ目のモデルの出力に応じて1つ目もしくは2つ目のモデルを呼び出して予測
- 上記の問題は。1つ目のモデルのtrue labelがないこと。1つ目のモデルが間違った場合、2つ目3つ目のモデルは今まで見たことのないような入力で予測をする羽目になる。
- 解法
- usualかunusualかを予測するモデルを作る
- usualケースを予測するモデルを作る
- unusualケースを予測するモデルを作る
- 2つ目と3つ目のモデルの出力を入力にするモデルを作る(これが最終出力)
- 注意点:他のパターンと違いこのパターンはベストプラクティスとは限らない。複雑である。パフォーマンス悪くなるかも。MLの問題を分割するのは一般的に良くない。なぜならばMLは複数の要素が絡んだものを学習する能力が備わっているから。
Design Pattern 9: Neutral Class
薬処方でイブプロフェンかアセトアミノフェンどちらを処方するか?というbinary classificationではなく。どちらでも良いというneutralなクラスを追加するという話。全然関係ないけど null object pattern を思い出した。
Design Pattern 10: Rebalancing
- 問題: 特定のクラスのデータが少ないとモデルがそのクラスの分類を学習してくれない。
- 解法
- 適切なevaluation metricを選ぶ
- F-measureとか。test set はオリジナルデータセットと同じバランスでなければいけない。
- Downsampling
- majority class のデータ数を学習時に減らす。
- ensembleと組み合わせることが多い。その場合はmedianをとる。減らす majority クラスをその度にランダムに変えてモデルを学習すれば良い。
- Weighted classes
- Kerasならclass_weight で特定のクラスが重要だよとモデルに教えることができる。=> よく効いた
- Output Layer Bias
- class weightに追加してモデルのoutput layerのbiasをimbalanceを加味してセットする。=> 効いた
- Upsampling
- 特定のクラスのデータを複製して増やしたり、生成する。down samplingと合わせて行われる。
- SMOTE は生成を自動でやってくれるアルゴリズム。
- Cascade パターンも使える
- down sampling と class weightを組み合わせることもできる。down sampling 後のバランスに合わせてclass weightを設定する。
- SMOTE を利用したover sampling も試して効いた。
- 適切なevaluation metricを選ぶ
Design Pattern 11: Useful Overfitting
- 意図的に training data に overfit して利益を得る。
- 以下のような場合には overfitting が望ましい
- input が物理ベースのもので数式で precise state が計算できる場合など。それを模倣するように model に学習させる場合は overfitting させるべき。
- Distilling bigger model の場合も。小さなモデルは bigger モデルが生成した training data に overfit すべき。
Design Pattern 12: Checkpoints
- 学習時間が伸びるにつれてエラーで止まった時のコストが高い。checkpoint を保存しておけば途中からトレーニングを再開できる。
- 作者も書いていたがこれは実は簡単ではなくて、learning rate とか optimizer なども復元しないといけない。Colab がもっと弱かった頃はかなり頑張って resume できるようにしていたが最近はサボってる。
Design Pattern 13: Transfer Learning
- pretrained model の final output layer を取り除き(正確には flatten 以降)モデルを nontrainable にする。final layer をすげ替えて学習すれば完成。以前 Kaggle のコンペの public notebook でこの方法を学んだが。なぜうまくいくのか?を直感的に理解していなかったので良い学びがあった。著者らが公開しているnotebookは必ず実行してみるべき。驚くほど短い training でそれなりの精度が出る。
- fine-tuning は完全に nontrainable にするのではなくて一部のlayersをtrainable にする。
- その分学習に時間がかかる
- train data が多く。元のモデルと同じ種類のデータの場合はこちらの方が効くかも。
- Transfer learning は text & image がメインだが TabNet は tabular data で良い結果を残しつつある。
Design Pattern 14: Distribution Strategy
- データ量とモデルのサイズは大きくなるばかり。シングルGPUだと学習時間が14 daysとかも。
- 方法は2つ
- data parallelism
- 各ワーカーが training data のサブセットに対して処理をする
- synchronous training
- 各ワーカーはモデルのコピーを持っていて forward 後 gradient を計算。各ワーカーの gradient を集約して中央サーバーが gradient step してモデルパラメータを更新。最新のモデルを各ワーカーに渡す。
- 待ち合わせやワーカー同士のコミュニケーションで overhead がある。
- 1つのマシン+ multiple GPUs だと速くできる。
- overhead があるので batch size を可能な限り大きくするべき。ただし val_loss が急激に大きくなる場合があるので注意。
- asynchronous training
- 各ワーカーの gradient を集約せず、asynchronous でパラメータを更新するのでスループットが高い。
- model parallelism
- model が分割され各ワーカーはモデルの一部を担当する
- data parallelism
Design Pattern 15: Hyperparameter Tuning
- 全ての組み合わせを試すのは無理。
- keras-tuner library (Baysian optimization)
Design Pattern 16: Stateless Serving Function
- 問題
- 解法
- Model export: learning rate, drop-out など不要なものを取り除いて model の数学的なコアのみを export する
- Inference: serving_fn として取り出して実行する
- Web endpoint: Cloud function などで stateless に export する
仕事でMLしたことがないので。production deployment の話は面白い。Web フレームワークという成熟した技術基盤に乗せてしまい。監視・スケーラビリティなどを任せようというすっきりした解法であった。
Design Pattern 17: Batch Serving
- 問題: 1つのリクエストで全ユーザーのプレイリストを作るようなユースケースではどうすれば良いか?
- 解法
- Distributed Data Processing (BiqQueryなど) で簡単にできるよ。
Design Pattern 18: Continued Model Evaluation
- 問題: Model を deploy して終わりではない。production でも意図通り動いているか?もし動かなくなったら検出できる?
- 解法
- モデル性能悪化をモニタリングする。そのためには raw_data, ground truth, prediction が必要。
- Serving 時にサンプリングして raw_data, prediction を保存。ground truth は通常遅れて入手されることが多い。
- これも Kaggle では学べないもの。継続的にモニタリングして性能が意図通りか確認することは予想できていたが、ground truth の入手は serving 時よりかなり遅れることがある。などの課題には気づいてなかった。counterfactual も考えると難しいね。
Design Pattern 19: Two-Phase Predictions
- 問題: ユーザーの device で prediction したい時がある(フィットネスアプリとか)。その場合はモデルのサイズなどトレードオフがある。
- 解法: 問題を2つに分ける。シンプルで edge で実行するもの。それを引き継いでクラウド側でやるもの。例: Google Home。
Design Pattern 20: Keyed Predictions
- 問題: 大量の入力に対する出力は分散して predict される。分割された output を元の input に対応する形で整える必要あり。
- 解法: client に入力とともに key を指定させる。
Design Pattern 21: Transform
- 問題: Model への input は実際に model が計算に使う形式とは限らない。入力は text だが計算に使うのは embedding vectorとか。training 時とprediction時の何らかの入力の違いによるミスは大問題。
- 解法: input を feature にする部分をきちんと認識して分ける(Transform)
- 驚くべきはBigQuery がTransform句をサポートしていること。こういう間違いが起きない強制力は素晴らしいと思う。prediction 時だけ特定の feature engineering 忘れるとかなくなる。
- Tensorflow は feature engineering をグラフに含める方法をサポートしている。tf.keras.layers.Lambda でやるやつ。
- cons: feature engineering とモデルを分けられないので、別モデルを試しづらい。feature engineering のキャッシュが難しい。feature engineering の結果のデータ分析が難しい。
Design Pattern 22: Repeatable Splitting
test, train, valid のデータ分割の話。Kaggle で実地で学んだので略。
Design Pattern 23: Bridged Schema
- 問題: デリバリーのチップ額を予測するモデル。支払いタイプが現金とカードで予測するモデルがある。データ元の改善によりカードの詳細が取れるようになった(gift, debit, credit) 。今すぐにでもこの有用なデータでモデルと学習し直したいがまだデータが少ない。どうするか?
- 解法
- 古いデータの schema を新しいデータにマッチするようにブリッジする。新しいデータは可能な限り全て、古いデータは augment してモデルを学習する。
- スキーマをブリッジするとは?古いデータの支払いタイプカードは本当は新しいデータタイプの gift, debit, credit のどれかだったはずだがそれは記録されていない。これを probalistically or statically にブリッジできる。
- Probabilistic method: 新しいデータではカード種別の割合が分かっているので(例: 10%, 30%, 60%)古いデータをロードするたびに一様分布から0-100数値を取り出す。それに応じて古いデータのカード種別を設定する。
- おすすめStatic method: カテゴリカル変数は one-hot encodingされることが多いので。古いデータの支払いタイプは [0, .1, .3, .6] とする。新しいデータの方はそのまま [0, 0, 1, 0] などとする。
- 他にやること
- まず新しいデータから十分な evaluation データをとっておく。件数は evaluation metrics が安定するくらいに。
- bridge する古いデータの件数を決める。
Design Pattern 24: Windowed Inference
- 問題: 空港の発着の遅れについて。「通常より遅れているか?」を判定したい。時間帯によって遅れの傾向は違うので2時間のタイムウィンドウの中で異常値加判定する。prediction 時にはどうすれば良いのか?
- 解法
- モデルの state を時間に沿って保存する stream processing を実行する
- フライト到着時間のスライディングウインドウを作る。ウィンドウは2時間で終わるが10分ごとに閉じる。つまり10分毎に過去2時間の集約値を計算する。
- モデルの内部stateは新しいフライト情報が入り次第更新される。
- ウィンドウが閉じるたび(この例では10分毎)に time series ML モデルが2時間のフライトリスト情報で学習を行う。そしてこのモデルはこれから未来のpredictionに使われる。
- time series モデルパラメータは状態変数として外に保存される。LSTMの場合model weightがこれに当たる。
- このシンプルな例ではモデルパラーメタは2時間ウィンドウの平均遅延時間と偏差になる。
Design Pattern 25: Workflow Pipeline
- モデルの state を時間に沿って保存する stream processing を実行する
- end to end の model deploy運用をコンテナ化で行うという。もっともな内容。まあそうですよね。
Design Pattern 26: Feature Store
- 問題: Feature engineering はad hocかつone offになりがちなのでプロジェクトや組織をまたいだ共有が難しい。
- 解法: 一箇所にコードとドキュメントをまとめてそこを使うようにする。オープンソースの実装もいくつかある。
Design Pattern 27: Model Versioning
Design Pattern 28: Heuristic Benchmark
- 問題: 自転車レンタル使用時間の予測モデルのtest set に対する MAE が 1200 秒である。これはビジネスの観点から良いか悪いのか?特にこれが初めて作ったモデルだと比較対象がない
- 解法: 直感的に理解でき、比較的簡単に計算できるmetricsを定義する。 Table 7-1の例がとても良い。
Design Pattern 29: Explainable Predictions
- 問題: test set に対する MAE などの指標が分かってもそれだけではユーザーからの信頼は得られない。なぜその結果になったのか説明してほしい。もしかしたら意図しないbiasをもとに判断しているかも。
- 解法: feature attributions。各々のfeatureがどの程度出力に寄与したかを求める。
- Instance level attributions: 各予測に対して attribution を求める。例)特定の決済がなぜ承認されたか?
- Global attributions: モデル全体として attribution を求める。instance level の平均と言っても良い。例)飛行機の遅延時間予測では天候が一番原因となっている。
- ここで SHAP 登場。
Design Pattern 30: Fairness Lens
- 問題: 学習データやパイプラインのどこかで問題のあるバイアスが入り込むことがある。
- 解法: 学習前にバイアスを特定し、学習したモデルを Fairness Lens を通して評価する。モデルとデータで全てのユーザーグループを平等に扱う。
- Training 前
- Data Analysis をして Data bias を見つける。例) race, gender などが balanced かどうか。classification problem なら label が balanced かどうか?data label をする人の主観 bias はないか?
- 上記 balance を維持したまま train, test, valid のデータ分割を行う。
- What if tool が便利そう
- Training 後
- model に bias が入り込むことがある。原因はデータにあった未発見のbias、モデルアーキテクチャ、optimization metrics など。
- training 後の model を What if tool に渡して test set に対する prediction を見てみる
- Training 前
MATHEMATICS FOR MACHINE LEARNING の読書記録
いくつかの Kaggle competitions を経験し数学の復習が必要だと気づいたので Mathematics for Machine Learning を読む。まずはトライアルで2章を読み切る。新・数学の学び方 を参考に以下のルールで読みすすめる。
- 数式を完全に分かるまで追う。
- 実際に手を動かして同じ式変形をする。分からない場合は覚えるまで式変形を繰り返す。
- 記録をここに残す。
- どうしても分からないところは誰かに質問する。
- これがうまくいくようであれば仲間を募る?
- https://mml-book.com
読後の感想など
数字
- 355 ページ 12章
- 70日
- GoodNotes の手書きノート407ページ
なぜ読んだか
冒頭にも書いたが Kaggle Indoor コンペでチームメイトの Saito さんのやっていることが分からなかったのが直接の動機。それ以外にも Discussions で線形代数の基礎が分かっていれば深い理解が得られそうな場面もあった。 なので機械学習をからめて線形代数を網羅的に勉強したかった(正確には復習)。
何を得たか
以下の2つが大きい。
- 70日間ほぼ毎日、数式を書く・追うことを繰り返して勘を取り戻していった(助けて下さった Twitter の皆さんには感謝しかない)
- 網羅的に勉強したのだから大丈夫。という謎の安心感。(これはCSを網羅的に学習したときも感じた。)
Twitter での記録 (上が最新)
- すべてのノート
- 12章
- 11章
- 10章
- 9章
- 8章
- 7章
- 6章
- 5章
- 4章
- 3章
2章
- 2021/6/16 朝。Exercis 2.20 終わった。 e と f の答えが合わず悔しい。どこで間違った。これにて2章読了。合計20日・ノート117ページ。サポートしてくださった。@Ak141J, @kengohirachi, @__garzon, @NeXTSTEP2OSX, @TwShotaro , @melonsode (敬称略)本当にありがとうございました。3章も挫折禁止でいきます。
- 2021/6/15 夜。Exercise 2.20 d まで。もう少し
- 2021/6/15 朝。Exercis 2.15 G={(a-b, a+b, a-3b)|a,b∈R} の basis の求め方が分からない。(a-b, a+b, a-3b) が basis かとも思ったが a,b∈R なので定まっていないから違う。(a-b, a+b, a-3b) = (a-b)[1 0 0]T + (a+b)[0 1 0]T + (a-3b)[0 0 1]Tと書けるから the canonical basis でよいのだろうか
- 良くない。詳細は__garzon@さんのコメント。
- 2021/6/14 Kengo Hirachi (@kengohirachi) さんによるヒント で Exercise 2.12 光が見えた。本当に感謝。
- 2021/6/13 Exercise 2.12 で突然 basis of U1 ∩ U2 を求めろと言われお手上げ。そもそも intersection について言及なかったはず。
- 2021/6/12 Exercise 2.5 まで。2.2 はぱっと見の難しさがすごい。読み解くとギリギリ分かる範囲。
- 2021/6/11 (1) Rank Nullity Theorem の唐突感。何がうれしいのか分からず戸惑う。(2) Affine subspaces のところで間違いを見つけて errata 見たら修正されてた。(3) というわけで2章は Excercises を残すのみ!
- 2021/6/10 Image and Kernel の Definition 2.23 まで。Basis Change は数式が多かった。おかげで飛躍が少なく理解しやすかった。Kernel/null space と書いている割に文脈によっては null space を多用しているけど ker(φ) と。面白い。
- 2021/6/9 Theorem 2.20 (Basis Change) の途中。やりたいことの背景は分かるのであとは式を丁寧に追うだけのはず。
- 2021/6/8 (2.94) は https://twitter.com/Ak141J/status/1401922706858135554 において @Ak141J さんが教えてくださった。方法で完全に納得しました。
- 2021/6/10 更新。Nyoho@NeXTSTEP2OSX さんに間違いをご指摘いただいたので修正。このスレッドから追える。
- 2021/6/5 式 (2.94) がやはり分からない。あいまいな理解を減らすために 2.7.1 を全体的に見直して 2.94 直前までは理解できたのだが分からない。明日もうすこしネットで同じ内容のものを探そう。
- 2021/6/3 (2.94) まで。Example 2.21 がが理解出来ないので明日も続ける。任意のx∈V, y∈Wのlinear mapping について話していたのにいつの間にか basis の変換の話に。
- 2021/6/2 (2.84)まで。generating set, basis, rank 。新しい概念がたくさん。rankは分かったような分からないような。
- 2021/6/1 (2.76)まで。Linear Independence をクリア。定義、例、直感的な説明、手を動かしてようやく理解できた気がする。
2021/5/31 Example 2.12 まで。Example 2.12 内の The intersection of arbitrarily many subspaces is a subspace itself. がしっくりこない。
- Kengo Hirachi (@kengohirachi) さんによるコメント 参照。いつもコメントくださってありがたい。
2021/5/30 事情により時間を取れず
- 2021/5/29 式(2.64)まで。Gaussian Elimination の計算に苦労した。Group を学んでからの Vector Spaces の定義は分かったような分からないような。
- 2021/5/28 式(2.53)まで。きちんと追えたと思う。
- 2021/5/27 式(2.45)まで。式(2-40)から(2-43)が最初全然分からなかった。Ax=b の解 x=x' 。Ax=0 の解 x=x'' はA(x'+x'')=b を満たすので x'+x'' は Ax=b の解であることは分かる。だがなぜそれが一般解なのか。Ax=0 を満たす解を2種類求めているのはなぜなのか?が分からなかった。
- 2021/5/26 式(2.37)まで。さすがに覚えている内容だが式をきちんと追った。
1章
- 2021/5/26 本書の読み方的な章。
Indoor Location & Navigation コンペ振り返り
Indoor Location & Navigation というコンペで9位入賞。目標だった Kaggle Master になったので振り返り。これはチームメイトである @KaggleSaito さんとの成果である。
どういうコンペか?
与えられたスマホセンサーデータ(Wifiなど)からショッピングモールでのフロアと位置を推定する。これがうまくいけば、例えばイオンモールの無印の近くにいるときに適切なクーポンをユーザーに届けられるかもしれない。
評価指標
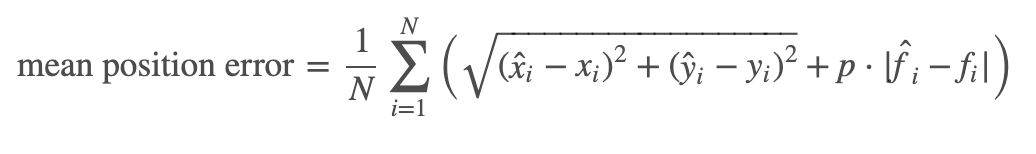 大まかに言うと真の (x, y) との距離が小さければよい。何階か?を外すと大きなペナルティ。
大まかに言うと真の (x, y) との距離が小さければよい。何階か?を外すと大きなペナルティ。
自分のモデル
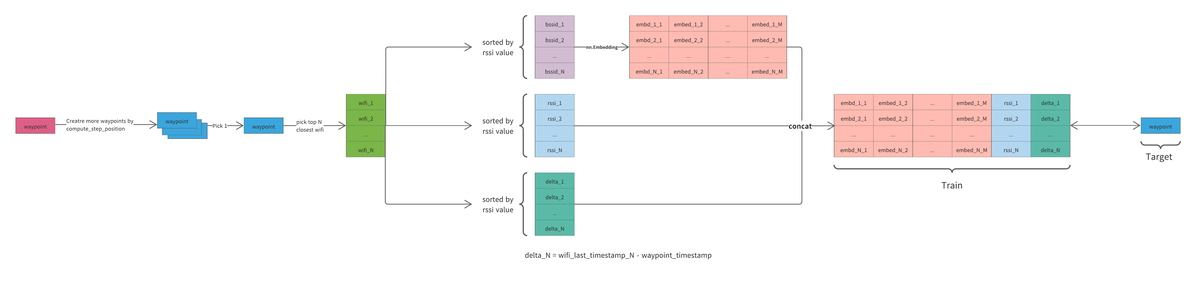 他のチーム同様 Wifi データをメインに LSTM/GRU のモデルで位置を推定し、post processing で精度を高めた(大きな画像へのリンク)
他のチーム同様 Wifi データをメインに LSTM/GRU のモデルで位置を推定し、post processing で精度を高めた(大きな画像へのリンク)
{kind=link}
他のチームとの差別化要因は
- Training Data を水増しできたこと。コンペの host が提供する utility 関数に ``compute_step_postion``` という関数がありセンサーデータを人間の歩み(step) に変換できる。これを以下で述べるアプローチと組み合わせると精度が上がった。
- Kouki さんが Shareししてくれた Wifi データを LSTMにに入力する方法の視点を変えて、より自然な waypoint ベースの training set を生成した。
- Saito さんの提案ではじめた Pseudo Labeling がよく効いた。
- LSTM/GRU の Stacking。
- Saitoさん主導の Post Processing。
- floor image を利用しての hallway map を作成。
- hand labeling ではない waypoint の生成
試したがうまく行かなかったもの
- Transformer
- hallwayからハズレた場合に大きなペネルティを与える custom loss(実装大変だった)
作業環境・実験管理
- Colab Pro のハイメモリをメインで使った。データのサイズが大きくメモリに載せるのが大変だった。ML力よりもエンジニアリング力がある自分としてはとても有利だったと思う。
- Colab Pro は notebook 機能はほぼ使わず。安価に GPU が使える実行環境として利用した。
- 実行環境の入出力(データセット)は API を利用して Kaggle Datasetを使う
- 以前は Google Drive だったが圧倒的に Kaggle datasetののほうが良かった。
- 実行ボタンを押すと、Kaggle dataset からデータダウンロード、実行 scriptを git からチェックアウト。学習が終わったら結果を Kaggle dataset にアップロード。
- 各実験ごとに番号を振り、その notebookで実行ボタンを押せばすべてが再現するようにした。
- コーディングは Localの Visual Studio Code on Macで。
- Docker は非力なローカルマシンでは足枷にしかならなかったので今回はやめた。
- 実行環境の入出力(データセット)は API を利用して Kaggle Datasetを使う
自分が伸び悩んでいたところがわかった
自分は長らく金メダルが取れずに伸び悩んでいたのだが。どうすればよかったのかがようやく分かった。
データをよく見ること
EDA しよう。データを良く見ようとはよく言われることだ。本にも書いてある。分からないなりに EDA notebook を作り visualize したことは何度でもあるか正直ピンときてなかった。今回うまく行った方法は、他人が書いたデータプロセスコードを行レベルで完全に理解し数倍に高速化すること。その過程で「分かった」と思っていたが全然肌感覚で理解していなかったデータの関係が見えてきた。そして高速化・自分のコードに書き直したことでその先のステップに進みやすかった。
ツールや API への習熟
これも当たり前すぎるかもしれない。有名な Grand Master Abhishekさん のYouTube 動画を見たときに衝撃を受けたのを覚えている。pandas の各種機能 keyward 引数など調べずにスラスラ書いていた。一方自分はすべて検索しながらコピペしながらである。
このコンペでは上記の高速化があったので、たくさんコードを書いた。今なら何も見ずに pandas の groupby や LSTM モデル・データセットのコードを書く自信がある。
Visual Studio Code キーバインディング微調整
- Command Palette にアクセスするキーバインドが動いていない気がする
- ctrl + ; に割り当てた
- when expression を空にしないと動かなかった
- Go to Definition
- cmd + t
- Go Back
- cmd + r
- Ctrl x b が効かない。
- Karabiner-Elements がバッティングしてた。Karabiner-Elements の設定から Ctrl-x as prefix を消した。
Riiid コンペ復習 - maskingなど
これは Riiid! Answer Correctness Prediction | Kaggle において自分が理解できていなかった部分をまとめるもの。間違いを含む可能性がある。間違いを見つけたら @higeponja にお知らせください。
Riiid はいわゆる time series コンペ。きちんと masking をしないとleakage が発生する。このあたりの自分の理解をまとめる。
未来の情報を使ってはいけない
train/infer 時のマスク
未来の情報を train/infer 時に使ってはいけない。これを厳密にやらないと leakage になる
- Transformer の attention で未来を見てはいけない。例)問題番号 102 の正解・不正解が分かれば、以前の問題101の予測は簡単になるかもしれない。いわゆる triu マスク。
- task_container_id を共有する問題は、すべての問題を解き終わらないと答えを知ることができない。これは Riiid 固有の話。そのため未来を参照しないマスクとあわせてもう1つマスクが必要。下記 task mask 参照。src_mask, tgt_mask, memory_mask すべてに同じマスクが必要。

train & validation split
厳密には train/valid を split するときに task_container_id を分断してしまうと leakage が発生する。これの影響は軽微であるというコメントもあった。なぜならそれは分断面のみで起こるからデータが大きければ影響が少ないからだと思われる。
pad を参照しない
loss 計算時に pad 部分を mask する。
auc 計算
今回の Transformer 系の解法ではデータを右側に寄せる解法が多かった。これは長さの異なる input でも必ず seq[-1] が求める prediction になるから。このことから auc 計算時にはseq[-1] のみを計算対象とするべきだったようだ。
間違い、新発見があれば追記するかも。
Google Football コンペ
銅メダルでした。
- 以前のRLコンペから学んでやらなかったこと
- DQN などの自前実装:自分の学習のためなら良いが、自前実装はバグりやすくたくさんの罠がある。すでに動いているベースラインが運営から提供されているのでそれを使う。そうすれば reward / observation の調整などの本質に集中できる。本コンペの場合は seed_rl ベースの notebook が提供されていた。
- 初挑戦したこと
- seed_rl を利用することで GCP の AI Platform に詳しくなった。間違った configuration で高額課金になってしまうことを恐れていたが、きちんと document を読んでいけば怖くないよ。
- やってよかったこと
- 失敗したこと
- 失敗ではないが GCP クレジット(or お金)がもっとあれば training で試行錯誤できた。
- seed_rl を TPU で動かすことが競争優位性となると思いがんばったが、実質不可能だった。早めに運営に質問すれば良かった。
- 大まかな試行錯誤の流れ
- 初期段階では自分のベースラインを作ろうと思い pfrl で簡単にデモを書いた。discussion で質問するにつれて seed_rl に勝てる部分がないことに気づき捨てた。
- observation については以前の RL コンペから直接画像を入力するのは問題外だとわかっていたので SMM を time series で 4 つ stack したものをそのまま利用。結局 observation を変更することはなく最終日までこのままだった。ちなみに stacking することを submission コードで考慮していなかったので序盤に score が伸びず悩んだ。
- reward はこれも score,checkpoint の両方がすでに用意されていてそれらがベースになった。kyohei さんが中盤から checkpoint reward を減衰させるコードを書いてくれた。agent が点数を入れられるようなってからは checkpoint は逆に足かせになるから。
- 最初から hard 相手に training するよりも徐々に対戦相手を強くしていくほうが学習効率と最終的にもっと強くなるらしいので試してみた。アイデアは簡単だが実装は gym env の理解が必須だったので真面目に取り組んだ。がんばれば difficulty を動的に変更できたので良かった。
- GCP + seed_rl でのトレーニング
- team のメリット
- kyohei さんに声をかけていただいてチームを組ませていただいた。ほぼ毎日 slack で議論して試行錯誤した。進捗の共有には dynalist を使った。チームを組むと自分に足りないものがよく見えてとても勉強になった。自分はもっと深くものを考えないといけない。つい浅はかな考えを元に手を動かしてます。
- もう一つのメリットはやはり心が折れないこと。仲間がいるとがんばれる。
Visual Studio Code + Docker for Kaggle
Kaggle 用の docker image が公開されているのでそれを Mac 上の Visual Studio Code 使う。
- やったこと
- Remote-Containers という拡張を入れて拡張経由で docker を使う。これは host と container 内の両方で Visual Studio Code を起動するので開発環境=実行環境になりうれしい。
- devcontainer.json に Container で起動する Visual Studio Code にインストールしたい拡張の記述
- 諦めたこと
- 想定する開発フロー
- Visual Studio Code で Container 起動。
- そのまま編集。
- Visual Studio Code の console で実行
- GitHub へのコミットは上記の通り